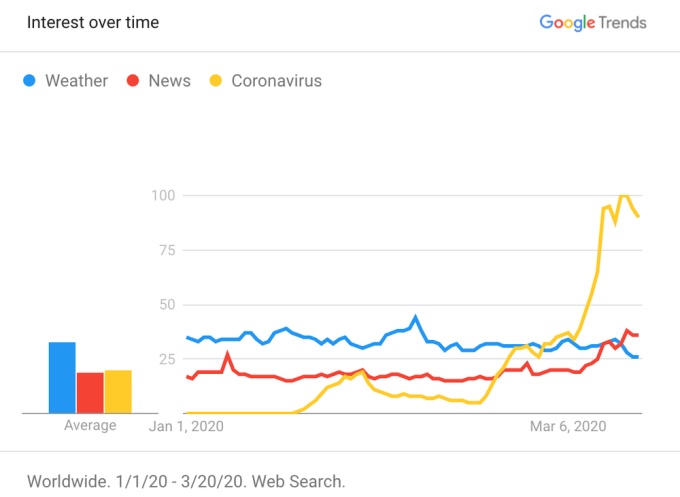
AWS today announced the preview of Amazon Location, a new service for developers who want to add location-based features to their web-based and mobile applications.
Based on mapping data from Esri and HERE Technologies, the service provides all of the basic mapping and point-of-interest data you would expect from a mapping service, including built-in tracking and geofencing features. It does not offer a routing feature, though.
“We want to make it easier and more cost-effective for you to add maps, location awareness, and other location-based features to your web and mobile applications,” AWS’s Jeff Barr writes in today’s announcement. “Until now, doing this has been somewhat complex and expensive, and also tied you to the business and programming models of a single provider.”
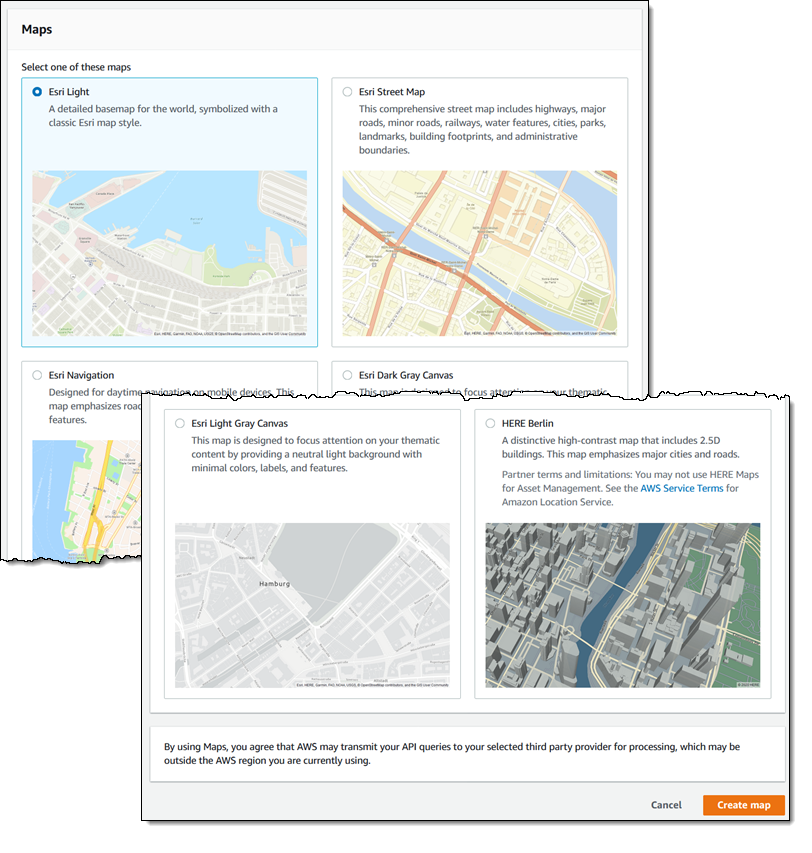
Image Credits: Amazon
At its core, Amazon Location provides the ability to create maps, based on the data and styles available from its partners (with more partners in the works) and access to their points of interest. Those are obviously the two core features for any mapping service. On top of this, Location also offers built-in support for trackers, so that apps can receive location updates from devices and plot them on a map. This feature can also be linked to Amazon Location’s geofencing tool so apps can send alerts when a device (or the dog that wears it) leaves a particular area.
It may not be as fully-featured as the Google Maps Platform, for example, but AWS promises that Location will be more affordable, with a variety of pricing plans (and a free three-month trial) that start at $0.04 for retrieving 1,000 map tiles. As with all things AWS, the pricing gets more complicated from there but seems quite reasonable overall.
While you can’t directly compare AWS’s tile-based pricing with Google’s plans, it’s worth noting that after you go beyond Google Map Platform’s $200 of free usage per month, static maps cost $2 per 1,000 requests.
After a number of pricing changes, Google’s mapping services lost a lot of goodwill from developers. AWS may be able to capitalize on this with this new platform, especially if it continues to build out its feature set to fill in some of the current gaps in the service.




 If you’ve managed to convince yourself that only large enterprises have the money to take advantage of Business Intelligence (BI), then think again. In the past, companies needed to hire expensive experts to really delve into BI. But these days, there is a range of affordable self-service tools that will allow small- and medium-sized businesses (SMBs) to make use of BI. What’s more, your SMB creates and holds much more data than you realize, which means you can start using BI for your business.
If you’ve managed to convince yourself that only large enterprises have the money to take advantage of Business Intelligence (BI), then think again. In the past, companies needed to hire expensive experts to really delve into BI. But these days, there is a range of affordable self-service tools that will allow small- and medium-sized businesses (SMBs) to make use of BI. What’s more, your SMB creates and holds much more data than you realize, which means you can start using BI for your business. Business Intelligence (BI) has conventionally been limited to big business; only they can afford pricey experts with specialist knowledge who can leverage BI’s value. But the rise of self-service BI tools has leveled the playing field, allowing small- and medium-sized businesses (SMBs) to get in on the game too. And with SMBs now producing far greater volumes of data than in the past, there’s never been a better time to put BI to use in your organization. Here’s what you need to know about BI.
Business Intelligence (BI) has conventionally been limited to big business; only they can afford pricey experts with specialist knowledge who can leverage BI’s value. But the rise of self-service BI tools has leveled the playing field, allowing small- and medium-sized businesses (SMBs) to get in on the game too. And with SMBs now producing far greater volumes of data than in the past, there’s never been a better time to put BI to use in your organization. Here’s what you need to know about BI.