It’s a busy week in the world of quantum computing and today Tel Aviv-based Quantum Machines, a startup that is building a software and hardware stack for controlling and operating quantum computers, announced the launch of QUA, a new language that it calls the first “standard universal language for quantum computers.”
Quantum Machines CEO Itamar Sivan likened QUA to developments like Intel’s x86 and Nvidia’s CUDA, both of which provide the low-level tools for developers to get the most out of their hardware.
Quantum Machine’s own control hardware is essentially agnostic with regards to the underlying quantum technology that its customers want to use. The idea here is that if the company manages to make its own hardware the standard for controlling these systems, then its language will – almost by default – become the standard as well. And while it’s a ‘universal’ language in the technical sense, it is — at least for now — meant to run on Quantum Machine’s own Quantum Orchestration Platform, which it announced earlier this year.
“QUA is basically the language of the Quantum Orchestration Platform,” Sivan told me. “But beyond that, QUA is what we believe the first candidate to become what we define as the ‘quantum computing software abstraction layer.’”
He argued that we are now at the right stage for the development of this layer because the underlying hardware has reached a matureness and because these systems are now fully programmable.
In his view, this is akin to what happened in classical computing, too. “The transition from having just specific circuits — physical circuits for specific algorithms — to the stage at which the system is programmable is the dramatic point. Basically, you have a software abstraction layer and then, you get to the era of software and everything accelerated.”
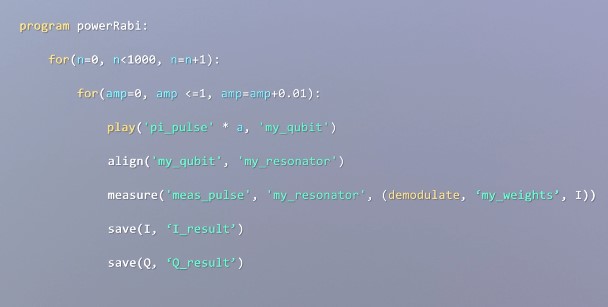
Image Credits: Quantum Machines /
Sivan actually believes that for the time being, developers will want languages that give them a lot of direct control over the hardware because for the foreseeable future, that’s what’s necessary to harness the advantages of quantum computing. “If you want to squeeze out everything quantum computers can give you, you better use low-level languages in the first place,” he argued,
For low-level developers, Sivan argues, QUA will represent a paradigm shift. “They shift from having to developing many, many things in an iterative way to actually having a language that can support even their wildest dreams — their while quantum algorithms dreams,” he said. “This is a real paradigm shift and these guys are experiencing in its full capacity — and it’s not only the accelerated process of programming and working, but also the capabilities themselves. Once everything is programmed in QUA and then compiled to the Quantum Orchestration Platform, then you also get the full benefit of the underlying hardware.”

Image Credits: Quantum Machines /
The company argues that its QUA language is the first language to combine quantum operations at the pulse level and universal classical operations. Quantum Machines also built a compiler, XQP, which can then optimize the programs for the specific underlying hardware, in this case, Quantum Machine’s Pulse Processor assembly language.
It obviously needs to do all of this in order to create an ecosystem and a community around its language. Of course, if its Quantum Orchestration Platform becomes widely used — and it already has an impressive list of users today — then QUA will also see wide adoption.
‘It’s one thing to build a beautiful language,” said Sivan. “But it’s another thing to develop it to be both beautiful and supported by an underlying hardware that is then adopted by itself. And then, the adoption of QUA is also led by the adoption of the Quantum Orchestration Platform, which is itself driven by the capabilities, nothing else.”