Shahin Farshchi
Contributor
More posts by this contributor
Sense and compute are the electronic eyes and ears that will be the ultimate power behind automating menial work and encouraging humans to cultivate their creativity.
These new capabilities for machines will depend on the best and brightest talent and investors who are building and financing companies aiming to deliver the AI chips destined to be the neurons and synapses of robotic brains.
Like any other herculean task, this one is expected to come with big rewards. And it will bring with it big promises, outrageous claims, and suspect results. Right now, it’s still the Wild West when it comes to measuring AI chips up against each other.
Remember laptop shopping before Apple made it easy? Cores, buses, gigabytes and GHz have given way to “Pro” and “Air.” Not so for AI chips.
Roboticists are struggling to make heads and tails out of the claims made by AI chip companies. Every passing day without autonomous cars puts more lives at risk of human drivers. Factories want humans to be more productive while out of harm’s way. Amazon wants to get as close as possible to Star Trek’s replicator by getting products to consumers faster.
A key component of that is the AI chips that will power them. A talented engineer making a bet on her career to build AI chips, an investor looking to underwrite the best AI chip company, and AV developers seeking the best AI chips, need objective measures to make important decisions that can have huge consequences.
A metric that gets thrown around frequently is TOPS, or trillions of operations per second, to measure performance. TOPS/W, or trillions of operations per second per Watt, is used to measure energy efficiency. These metrics are as ambiguous as they sound.
What are the operations being performed on? What’s an operation? Under what circumstances are these operations being performed? How does the timing by which you schedule these operations impact the function you are trying to perform? Is your chip equipped with the expensive memory it needs to maintain performance when running “real-world” models? Phrased differently, do these chips actually deliver these performance numbers in the intended application?

Image via Getty Images / antoniokhr
What’s an operation?
The core mathematical function performed in training and running neural networks is a convolution, which is simply a sum of multiplications. A multiplication itself is a bunch of summations (or accumulation), so are all the summations being lumped together as one “operation,” or does each summation count as an operation? This little detail can result in difference of 2x or more in a TOPS calculation. For the purpose of this discussion, we’ll use a complete multiply and accumulate (or MAC), as “two operations.”
What are the conditions?
Is this chip operating full-bore at close to a volt or is it sipping electrons at half a volt? Will there be sophisticated cooling or is it expected to bake in the sun? Running chips hot, and tricking electrons into them, slows them down. Conversely, operating at modest temperature while being generous with power, allows you to extract better performance out of a given design. Furthermore, does the energy measurement include loading up and preparing for an operation? As you will see below, overhead from “prep” can be as costly as performing the operation itself.
What’s the utilization?
Here is where it gets confusing. Just because a chip is rated at a certain number of TOPS, it doesn’t necessarily mean that when you give it a real-world problem, it can actually deliver the equivalent of the TOPS advertised. Why? It’s not just about TOPS. It has to do with fetching the weights, or values against which operations are performed, out of memory and setting up the system to perform the calculation. This is a function of what the chip is being used for. Usually, this “setup” takes more time than the process itself. The workaround is simple: fetch the weights and set up the system for a bunch of calculations, then do a bunch of calculations. Problem with that is that you’re sitting around while everything is being fetched, and then you’re going through the calculations.
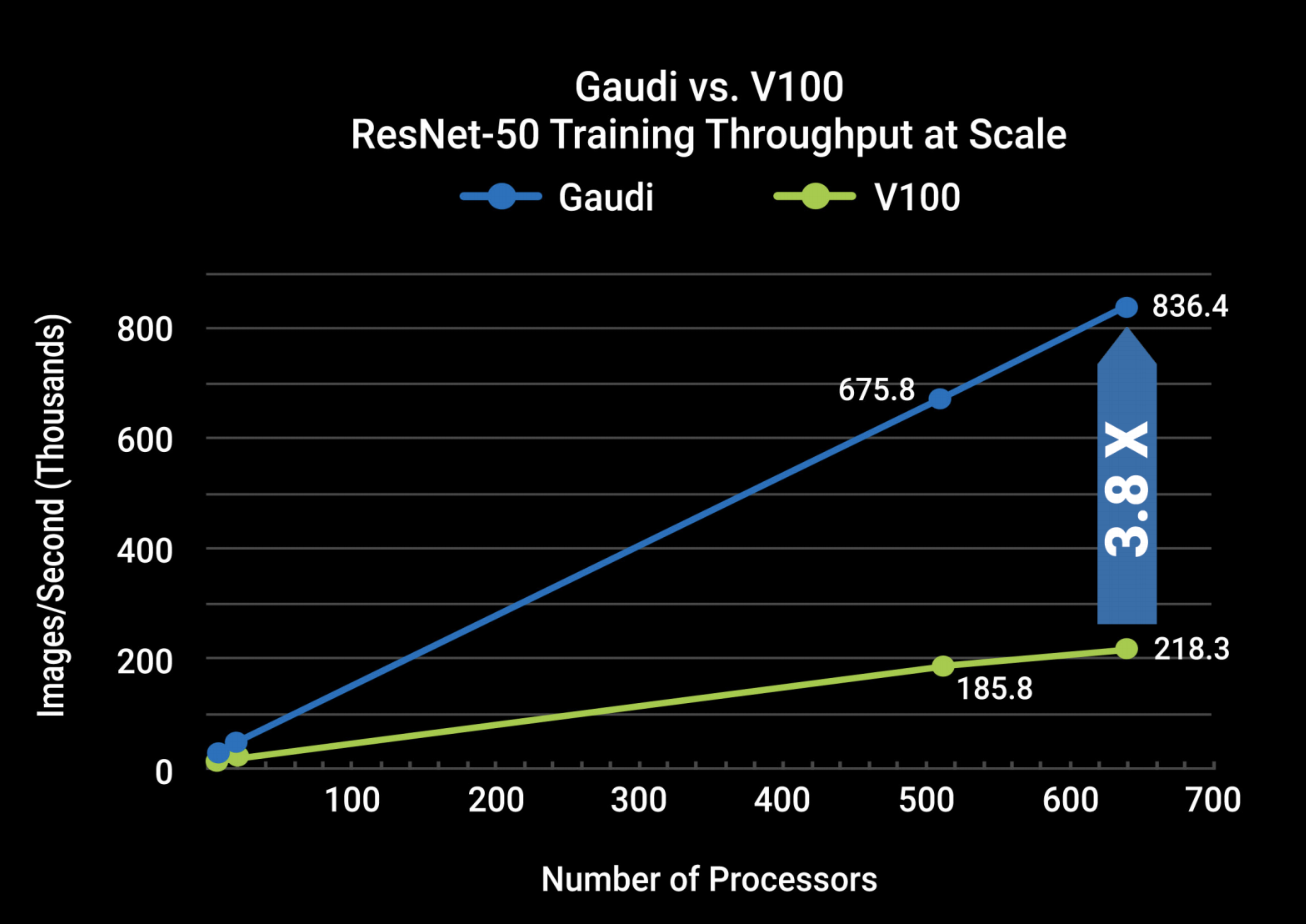
Flex Logix (my firm Lux Capital is an investor) compares the Nvidia Tesla T4’s actual delivered TOPS performance vs. the 130 TOPS it advertises on its website. They use ResNet-50, a common framework used in computer vision: it requires 3.5 billion MACs (equivalent to two operations, per above explanation of a MAC) for a modest 224×224 pixel image. That’s 7 billion operations per image. The Tesla T4 is rated at 3,920 images/second, so multiply that by the required 7 billion operations per image, and you’re at 27,440 billion operations per second, or 27 TOPS, well shy of the advertised 130 TOPS.

Batching is a technique where data and weights are loaded into the processor for several computation cycles. This allows you to make the most of compute capacity, BUT at the expense of added cycles to load up the weights and perform the computations. Therefore if your hardware can do 100 TOPS, memory and throughput constraints can lead you to only getting a fraction of the nameplate TOPS performance.
Where did the TOPS go? Scheduling, also known as batching, of the setup and loading up the weights followed by the actual number crunching takes us down to a fraction of the speed the core can perform. Some chipmakers overcome this problem by putting a bunch of fast, expensive SRAM on chip, rather than slow, but cheap off-chip DRAM. But chips with a ton of SRAM, like those from Graphcore and Cerebras, are big and expensive, and more conducive to datacenters.
There are, however, interesting solutions that some chip companies are pursuing:
Compilers:
Traditional compilers translate instructions into machine code to run on a processor. With modern multi-core processors, multi-threading has become commonplace, but “scheduling” on a many-core processor is far simpler than the batching we describe above. Many AI chip companies are relying on generic compilers from Google and Facebook, which will result in many chips companies offering products that perform about the same in real-world conditions.
Chip companies that build proprietary, advanced compilers specific to their hardware, and offer powerful tools to developers for a variety of applications to make the most of their silicon and Watts will certainly have a distinct edge. Applications will range from driverless cars to factory inspection to manufacturing robotics to logistics automation to household robots to security cameras.
New compute paradigms:
Simply jamming a bunch of memory close to a bunch of compute results in big chips that sap up a bunch of power. Digital design is one of tradeoffs, so how can you have your lunch and eat it too? Get creative. Mythic (my firm Lux is an investor) is performing the multiply and accumulates inside of embedded flash memory using analog computation. This empowers them to get superior speed and energy performance on older technology nodes. Other companies are doing fancy analog and photonics to escape from the grips of Moore’s Law.
Ultimately, if you’re doing conventional digital design, you’re limited by a single physical constraint: the speed at which charge travels through a transistor at a given process node. Everything else is optimization for a given application. Want to be good at multiple applications? Think outside the VLSI box!